博客发布过程
距离上次在这里敲下文字,已过去三个春秋。在这段“隐身”的日子里,思考从未停止,只是更多地沉淀在了Notion的角落。趁着岁未年初,我借助 Al的力量对博客底层进行了全面优化与“大扫除”,并将这几年的所思所想一并补齐。借助OpenCode与AI智能体进行协作,让原本繁琐的代码维护变得前所未有的便利,也让我能重新专注于内容本身。
Blog发布过程(Gitee -> Github -> GitHub Pages)
代码提交与托管: 您将基于 Hexo 框架和 Yelee 主题的源代码首先提交至 Gitee。这通常是为了兼顾国内开发的访问速度。
镜像同步 (Mirroring): 资料中提到“Mirror”这一技术标签。通过镜像机制,Gitee 上的更新会自动同步到 GitHub 的源码仓库,确保两个平台的代码版本一致。
自动化部署 (CI/CD): 一旦 GitHub 源码仓库接收到更新,会触发 GitHub Workflow(即 CI/CD 流程)。
◦ 该工作流会自动运行
hexo generate生成静态 HTML 页面。◦ 随后运行
hexo deploy或相关的 Action 脚本。多云分发:
◦ GitHub Pages 是主要的展示平台。
◦ 同时同步部署到 Netlify、Vercel、Render和 Cloudflare Pages。这种做法可以实现容灾备份和全球加速,确保无论用户身处何地都能快速访问您的博客。
这种“一次提交,到处发布”的折腾精神,非常契合“活着,就要折腾”以及“态度决定一切”的信条。
Github开源软件

Vibe Coding 四个开源项目复盘:从想法到可运行产品的 AI 协作方法
核心结论:Vibe Coding 真正有价值的地方,不是“让 AI 替你写代码”,而是把一个模糊想法快速推到可运行、可复现、可维护的状态。最近我借助这种方式连续做了四个开源项目:
daily-ai、term-cheat、html-ppt、claude-desktop-buddy-bridge。它们看起来方向不同,本质上都在解决同一个问题:把个人工作流里反复出现的痛点,沉淀成可以复用的工具。

GitHub Daily - 每日开源项目推送
核心结论:利用 GitHub Actions + 本地 Ollama 大模型 + Tailscale 加密隧道 + PushPlus 微信推送,打造每日自动推送 GitHub 热门开源项目的自动化流水线。
特性
- 自定义搜索 - 灵活配置搜索主题,如 AI Agent、Local LLM 等
- 本地 AI 总结 - 使用 Ollama 运行本地大模型,数据安全
- 流式生成 - 支持流式响应 (Streaming),防止跨网络连接超时
- 模型预热 - 自动预热加载模型,首字响应更迅速
- 安全连接 - 通过 Tailscale 加密隧道访问家庭电脑
- 微信推送 - 支持 PushPlus 免费推送
- 现代管理 - 使用 uv 处理依赖,极速环境搭建
- 调试工具集 - 内置全套 API 调试脚本,快速定位连接故障
Tailscale自建DERP服务器
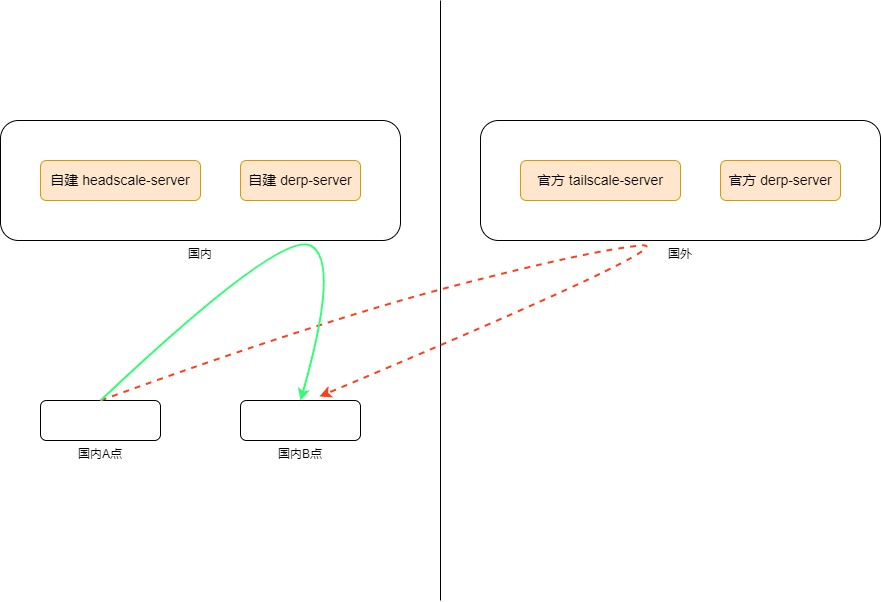
什么是DERP? DERP 即 Detoured Encrypted Routing Protocol,这是 Tailscale 自研的一个协议,它是一个通用目的包中继协议,运行在 HTTP 之上,而大部分网络都是允许 HTTP 通信的。 它根据目的公钥(destination’s public key)来中继加密的流量(encrypted payloads)。 Tailscale 会自动选择离目标节点最近的 DERP server 来中继流量。
Headscale-server 是取代官方server的开源服务器,更加灵活无现在。此文没有涉及到。
**Tailscale **使用的算法很有趣: 所有客户端之间的连接都是先选择 DERP 模式(中继模式),这意味着连接立即就能建立(优先级最低但 100% 能成功的模式),用户不用任何等待。然后开始并行地进行路径发现,通常几秒钟之后,我们就能发现一条更优路径,然后将现有连接透明升级(upgrade)过去,变成点对点连接(直连)。因此, DERP 既是 Tailscale 在 NAT 穿透失败时的保底通信方式(此时的角色与 TURN 类似),也是在其他一些场景下帮助我们完成 NAT 穿透的旁路信道。换句话说,它既是我们的保底方式,也是有更好的穿透链路时,帮助我们进行连接升级(upgrade to a peer-to-peer connection)的基础设施。
https://blog.csdn.net/u010470258/article/details/147090057?spm=1001.2014.3001.5506
https://www.ghostchu.com/tailscale-安利指南-快速向你的好友推销-tailscale/