核心结论:训练私有专用大模型,核心是明确目标→数据闭环→基座选型 + 算力匹配→分阶段训练调优→合规部署与迭代,全程严控数据与安全。
一、明确目标与方案规划(立项)
定义核心任务与指标:锁定垂直场景(如医疗病历、金融风控、工业质检),确定核心能力(生成 / 检索 / 推理 / 多模态);制定量化指标(准确率、F1、BLEU、Perplexity、响应速度、成本)。
合规与安全前置:数据合规(隐私脱敏、版权授权、GDPR / 个人信息保护法);模型合规(开源协议约束、出口管制、行业监管);建立数据与模型的访问权限、审计、加密机制。
算力与预算评估:训练侧(GPU 集群,A100/H100/H200,算力按参数量、数据量、训练步数估算);推理侧(模型压缩、量化、分布式部署);预算含硬件 / 云服务、人力、标注、合规、运维成本。
二、数据工程(核心,决定上限)
数据采集与合规处理
数据清洗与预处理:文本分词、归一化、过滤低质量数据;多模态数据统一编码、对齐;构建 prompt-answer 对(SFT 必备);数据增强(同义替换、回译、掩码、生成式增强)。
数据存储与版本管理:用对象存储、向量数据库、数据湖;建立数据版本,支持追溯与回滚。
三、基座选型与算力准备
基座模型选择
算力搭建 / 租赁
四、分阶段训练与调优(核心执行)
预训练(Pre-training,可选,成本高)
有监督微调(SFT,必选)
人类反馈强化学习(RLHF,可选,提升效果)
后训练优化(必选)
五、评估与测试(验收标准)
自动评估:用 BLEU、ROUGE、F1、Perplexity、准确率等指标;用第三方基准测试(MMLU、GSM8K、AGIEval 等)评估通用能力;构建领域专属测试集,评估专用能力。
人工评估:组织专业团队,按标注规范评估模型回答的准确性、完整性、有用性、合规性;开展用户测试,收集反馈。
安全与合规测试:测试模型是否存在偏见、歧视、有害内容生成;测试数据与模型的安全性(数据泄露、模型攻击);合规性审查(版权、隐私、行业监管)。
六、部署与运维(落地闭环)
部署方案
监控与运维
持续迭代:建立反馈闭环,收集用户反馈与业务数据,定期微调模型;跟踪行业技术进展,优化模型架构与训练方法。
七、关键避坑与建议
- 优先用 LoRA/QLoRA 等参数高效微调,避免全参数微调(成本高、周期长)。
- 数据质量 > 数据数量,高质量标注数据是 SFT 成功的关键。
- 合规与安全贯穿全程,避免法律风险。
- 从小模型、小场景、小数据起步,快速验证,逐步迭代。
- 建立专业团队(算法、数据、工程、合规、运维)。
微调基本概念
所谓大模型微调,指的在已有的大规模预训练模型基础上,通过对标注数据进行训练,进一步优化模型的表现,以适应特定任务或场景的需求。
不同于RAG或者Agent技术,通过搭建工作流来优化模型表现,微调是通过修改模型参数来优化模型能力,是一种能够让模型”永久”掌握某种能力的方法。
————————————————
版权声明:本文为CSDN博主「AI大模型产品经理」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Code1994/article/details/148762997
参考项目
- 绿城智能家居指令大模型
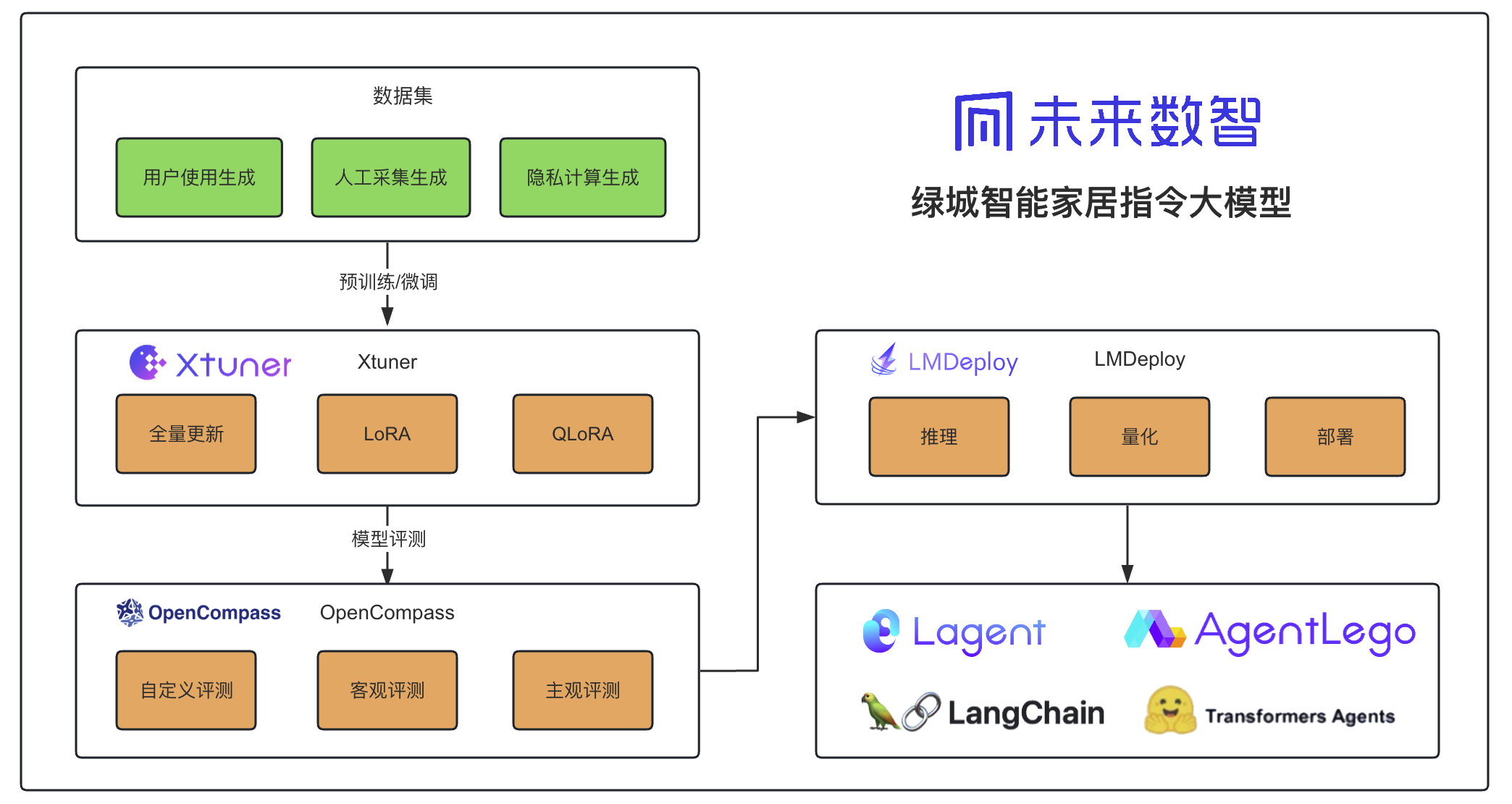
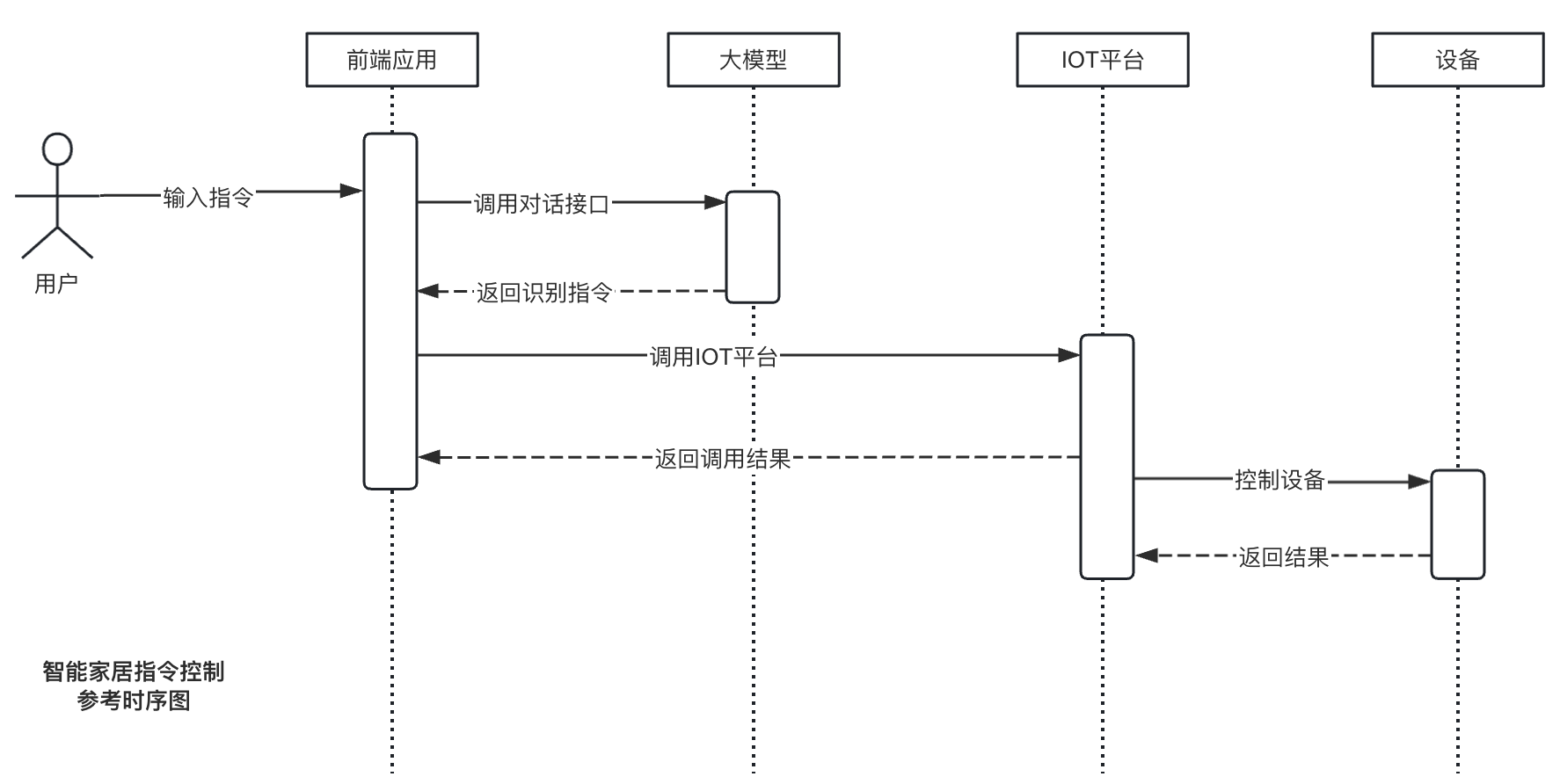
- 让智能家居”听懂人话”:我用4B模型+万条数据,教会了它理解复杂指令
https://blog.csdn.net/weixin_41851559/article/details/156013693